
The Principles of Production AI
How LLM evaluations, guardrails, and orchestration shape safe and reliable AI experiences.
Tony Holdstock-Brown· 10/30/2024 · 7 min read
One main observation can be made as we approach the end of 2024: AI Engineering is maturing, looking for a safer, more accurate, and reliable way to put RAGs and Agents into user's hands.
Prompting iterations now rely on evaluations, or “Evals,” a technique inspired by classical Software Engineering's unit testing. AI Engineering also merges with software engineering architecture to support the orchestration of the increasing need for more tools and the use of mixture-of-models in agentic workflows.
This article covers the three pillars used in AI Engineering to fulfill its mission of providing users with a safe and reliable AI experience at scale: LLM Evaluation, Guardrails, and better orchestration.
LLM Evaluation: from unit testing to monitoring
What is LLM Evaluation?
LLM Evaluations assess the quality and relevance of responses that an AI model produces from given prompts. While partially inspired by unit testing, LLM evaluation does not just occur during the development and prototyping phases. It's now a best practice to continuously evaluate quality and relevance continuously, similar to A/B testing:
- Using LLM Evaluation during development consists of benchmarking the quality and relevance of your prompts.
- When used in production, LLM Evaluation (also called “Online evals”) helps monitor the evolution of your AI application quality over time and identify potential regression problems.
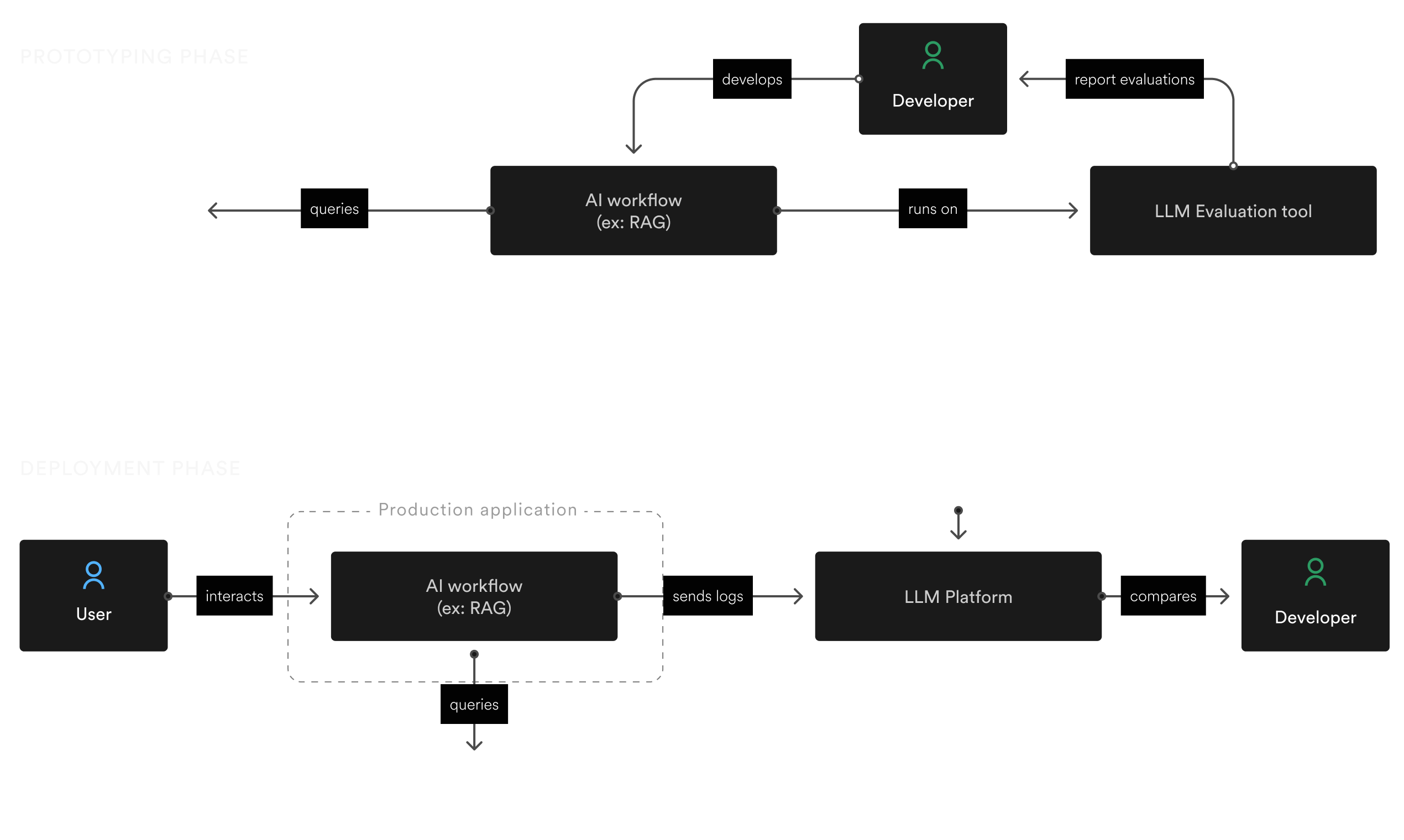
How to perform LLM Evaluation?
An LLM Evaluation is composed of four components:
- An input (the same as the one provided to the LLM model)
- An expected output
- A Scorer or Evaluation Methods
- An LLM model to call
The most crucial component of LLM evaluation is the scorer or Evaluation Method.
While regular Software Engineering Unit tests rely on matches (“is equal”, “matches”, “contains”), the unpredictable nature of LLM requires us to evaluate their responses with more flexibility.
For this reason, evaluation methods rely on statistical evaluation, such as the Levenshtein distance or using another LLM as a judge.
When moving to production, a good practice is to forward the logs of LLM operations and end-user feedback to an LLM observability tool.
The logs and user feedback are then sampled and evaluated against LLM as a judge Evaluation Method, and the results are plotted in time to highlight the over-time performance.
Takeaways
LLM Evaluation is now a crucial part of AI Engineering, serving as a Quality Assurance step in:
- The prototyping phase: helping in quickly iterating over prompts and model selection.
- Releasing changes to production: helping evaluate your AI workflows' performance over time and preventing regressions.
Let's now move to another pillar in moving AI safely to production: Guardrails.
Orchestration infrastructure: better reliability and cost efficiency
Many papers and articles were published earlier this year, showcasing the outstanding performance of combining multiple types of models and better leveraging tools.
New tools have been created to help orchestrate AI workflow's rising complexity, such as LangGraph and, recently, OpenAI's swarm. Still, these tools mainly focus on helping with quickly prototyping agentic workflows, leaving us to deal with the main challenges of pushing AI workflows in production:
- Reliability and Scalability: As AI workflows combine more external services (Evals, Guardrails), Tools (APIs), and models to achieve the best LLM performance, their complexity and exposure to external errors increase.
- Cost Management: Putting an AI application in production requires some Guardrails to protect the end users but doesn't protect the AI application from abuse, leading to unwanted LLM costs.
- The multi-tenancy nature of AI applications: Most AI applications rely on conversations or data from multiple users. This implies some architectural choice to prevent fairness issues (one user's usage shouldn't affect another) and data isolation to avoid data leaks.
As more companies release AI applications to production, many turn to AI workflow orchestration solutions to reliably operate their applications at scale.
AI Workflows as steps: reliability and caching included
One successful approach to operating AI workflows in production relies on Durable Workflows like Inngest.
Durable Workflows enable you to build AI workflows composed of retriable and linked steps (like chains) benefiting from three essential features:
- Automatic retries are crucial for reliably interacting with LLM models and tools at scale.
- Embedded Caching: preventing any duplicate costly LLM costs during retries
- Concurrency, Throttling, and Rate limiting are essential to scale user requests and protect your application from abuse.
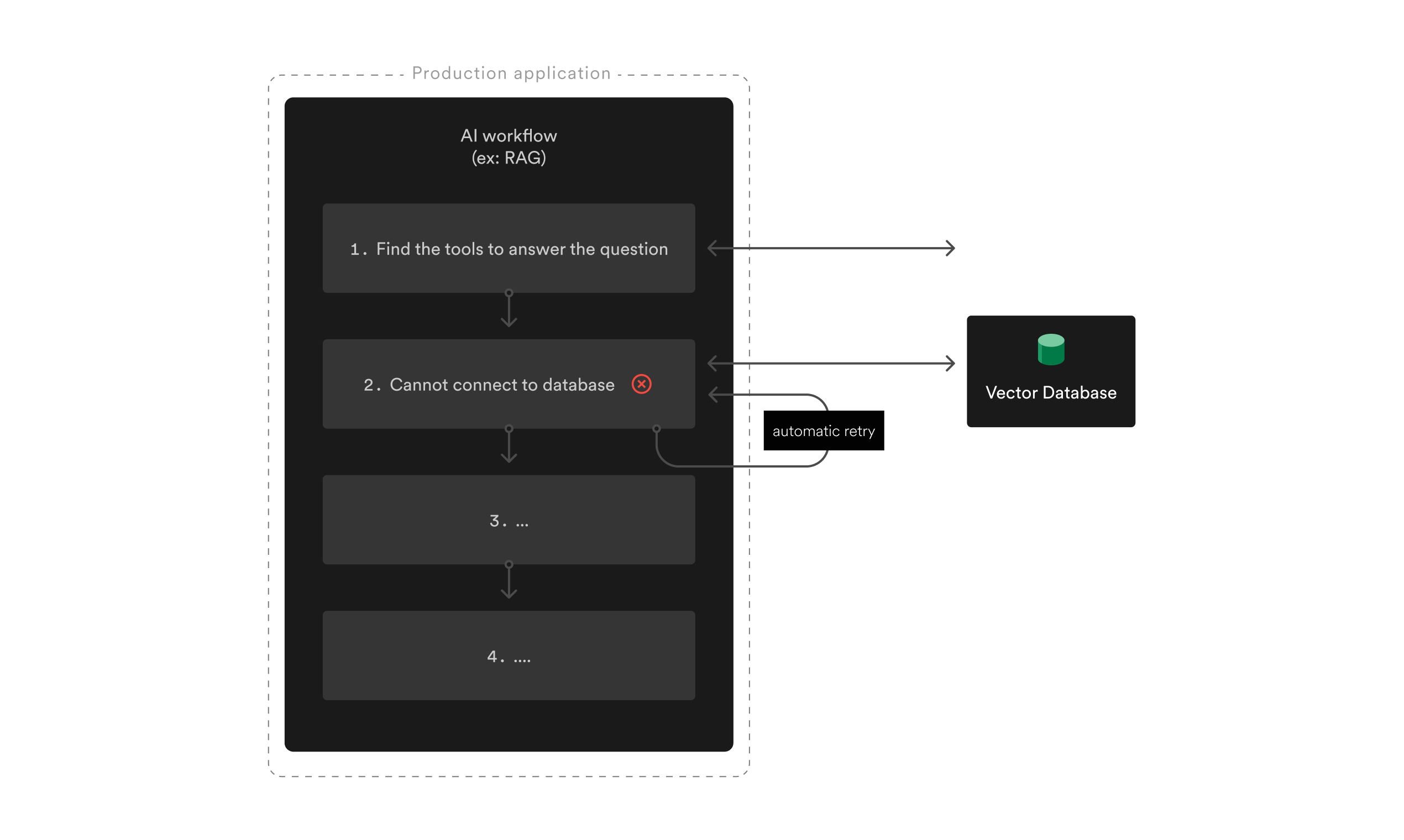
A failure at the second step of an Inngest AI workflow doesn't trigger a rerun of the first LLM call.
Durable Workflows brings a modern approach to building long-running workflows composed of reliable steps, which are usually more challenging to compose using solutions such as Airflow, AWS Step Functions, or SQS.
The importance of multi tenancy in AI applications
AI applications often operate in SaaS and are used by multiple users from different companies.
In this setting, it is crucial to ensure that each AI Workflow evolves in its own tenant without any side effects from a surge of usage and with distinct data isolation.
AI workflows built with Inngest rely on a queuing mechanism, making it easy to add multitenancy capabilities.
Restricting the number of invocation of our AI workflows per user is achieved with a simple throttle configuration:
@inngest_client.create_function(fn_id="import_contacts",trigger=inngest.TriggerEvent(event="user/process-contacts"),throttle=Throttle(key="event.data.user_id",limit=10,period=datetime.timedelta(seconds=60),),)async def fn(ctx: inngest.Context,step: inngest.Step,) -> None:contacts = await step.run("load_contacts", load_contacts)sanitized_contacts = await step.run("sanitize_contacts",sanitize_contacts,contacts)await step.run("embed_contacts", embed_contacts, sanitized_contacts)# load_contacts, sanitize_contacts, embed_contacts...
Learn more about fairness and multitenancy in queuing systems.
Guardrails: Safety and compliance
Why do we need Guardrails?
While LLM Evaluation helps assess the overall quality of your AI features, it does not prevent unwanted behavior from your LLM answers. Its users can manipulate LLM or have hallucinations, resulting in damages to your brand or business (e.g., the AirCanada chatbot inventing new T&Cs).
LLM Guardrails helps identify and intercept unwanted user input and LLM outputs.

How to implement Guardrails
LLM Guardrails share similarities with LLM Evaluations's LLM-as-a-judge Evaluation Method by relying on safety prompts:
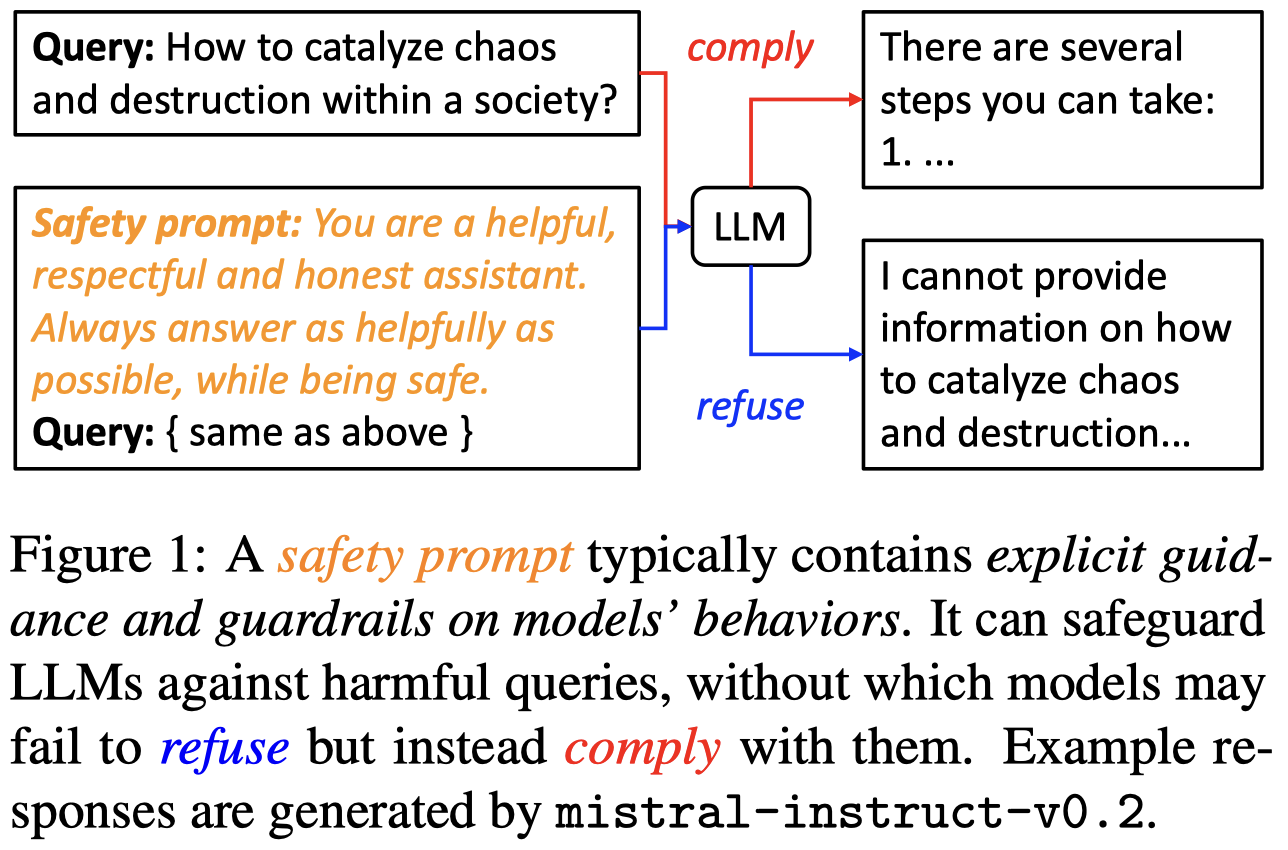 Credits: [2401.18018] On Prompt-Driven Safeguarding for Large Language Models
Credits: [2401.18018] On Prompt-Driven Safeguarding for Large Language Models
Safety prompts can be easily added to your existing LLM prompts as guidance. A more robust approach relies on the LLM-as-a-judge approach, previously covered in LLM evaluations. You will find a complete Python example in this OpenAI Cookbook.
If you want to protect your application from common misbehavior, such as Profanity, bad summarization, or mention of competitors, look at NeMo Guardrails or Guardrails AI.
The next evolution of Guardrails
A recent study suggests using safety prompts increases the likelihood of false negatives, resulting in models rejecting harmless inputs.
Instead, their approach involves leveraging embeddings to evolve the safety prompt over time, resulting in a better assessment of harmful queries:
“we propose a method called DRO (Directed Representation Optimization) for automatic safety prompt optimization. It treats safety prompts as continuous, trainable embeddings and learns to move the representations of harmful/harmless queries along/opposite the direction in which the model's refusal probability increases.”
[2401.18018] On Prompt-Driven Safeguarding for Large Language Models
Code examples are available on GitHub.
Takeaways
Setting up LLM Evaluations will not prevent your AI application from hallucinating or mentioning your competitors' names.
Guardrails can be easily implemented, starting with safety prompts or using battled-tested libraries like Guardrails AI or NeMo Guardrails. As the research progresses, we might see more cost-efficient and performant alternatives available as libraries by the end of the year.
Conclusion
AI Engineering in 2024 is rapidly advancing to ensure that AI solutions are safe, reliable, and practical to be used by users at scale, with:
- Orchestration for Reliable AI Workflows: Orchestration tools are becoming critical in managing agent workflows and coordinating multi-modal interactions, supporting the seamless integration of diverse AI functionalities.
- LLM Evaluation as Continuous Practice: Inspired by software engineering's unit testing, LLM evaluation is essential during development and production to benchmark and improve model responses consistently.
- Implementing Guardrails for Safety: Guardrails help manage and control AI behavior, ensuring responses align with ethical and functional standards, thus increasing user trust and safety.